
 Je me doutais bien qu’en arrivant, je le trouverais mal en point, le jeune cerisier planté au printemps dernier, après ces jours de canicule, et personne pour l’arroser. Effectivement, il était au bord du collapsus, les feuilles pendantes, certaines jaunes ou brunes, il faisait peine à voir, et il a fallu pas mal d’arrosage pour qu’il commence à reprendre allure.
Je me doutais bien qu’en arrivant, je le trouverais mal en point, le jeune cerisier planté au printemps dernier, après ces jours de canicule, et personne pour l’arroser. Effectivement, il était au bord du collapsus, les feuilles pendantes, certaines jaunes ou brunes, il faisait peine à voir, et il a fallu pas mal d’arrosage pour qu’il commence à reprendre allure.
Voilà où en est à peu près ce blog, sauf qu’il ne suffira pas de brancher le tuyau d’arrosage pour lui redonner vie, après plusieurs mois de silence, mais bien d’une discipline maintenue un bon moment, et sans presque personne pour me lire. Une audience se compose lentement, et se perd très vite : maintenant, il va falloir ramer sérieusement.
Bon, je vais commencer par essayer de gagner du temps avec un titre racoleur, genre « les 12 manières de [ceci] » ou « les 9 meilleurs [cela] ». Je pourrais promettre des révélations genre « tout ce que vous avez toujours voulu savoir sur... » ou « les coulisses de…« . D’ailleurs, c’est ce que j’ai fait, sauf que le titre est à la fois racoleur ET mensonger. Oui, oublions les 10 trucs, vous savez bien que je vais partir à la recherche d’un petit bout de web à commenter, et de liens vers où pointer, et que j’espérerai en intéresser quelques uns avec ça. Peut-être une conversation s’esquissera-t-elle dans les commentaires – mais j’en doute, je crains (et je ne suis pas la seule à m’en attrister) que cette période des blogs-salons-où-l-on-cause soit révolue.
Alors, quel petit bout de web à guidon chromé au fond de la cour ? Qu’est ce qui m’aura conduit cette fois à ralentir et stopper le défilement vertical dans Feedly (qui a remplacé pour moi le défunt Google Reader) ?
Le petit bout de web qui m’a donné l’idée de ce post, finalement, c’est un échange de tweets la nuit dernière (il faisait trop chaud pour dormir), un échange avec Clément Laberge et Sebastian Posth.
Clément a lancé la conversation en nous faisant part de sa « plus grande déception » :
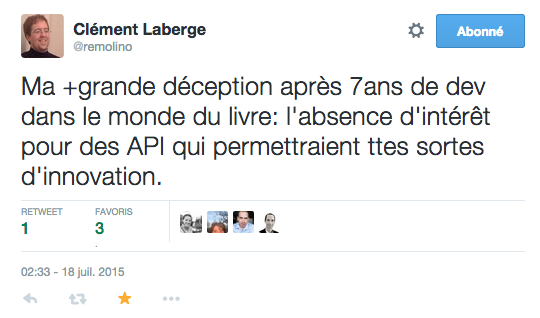
( Si le concept d’API n’est pas très clair pour vous, j’avais traduit un billet d’Hugh McGuire qui l’expliquait, qui plus est dans le contexte du livre numérique.)
Sabastian Posth a répondu en invoquant les DRM comme principale barrière au développement d’une stratégie d’APIs par les maisons d’édition, et ni Clément ni moi n’avons été convaincus : il y a un catalogue important, aussi bien au Québec qu’en France, de livres sans DRM, et on n’observe pas plus d’intérêt, ni du côté des éditeurs, pour la publication d’APIs, ni du côté des développeurs, pour développer sur les rares qui sont disponibles.
En repensant aujourd’hui à cette brève conversation nocturne, je me suis souvenue du billet qu’avait posté Christian Fauré en réponse à une question que je lui avais posée il y a déjà un bon moment ( en septembre 2008) : comment expliquer ce qu’est une API à un patron de maison d’édition ? :
« Mon sentiment, et je terminerai la-dessus, est qu’il ne faut pas chercher à convaincre le patron d’édition de mettre en place des APIs, mais lui indiquer que la mise en place des APIs requiert qu’un certain nombre de questions bien précises trouvent des réponses : à qui faut-il donner des clés d’accès aux données? y a t il un nombre de requêtes maximal par clé d’accès? quelles données sont accessibles ? quelles fonctions de manipulation des données sont offertes par les APIs ? quelles sont les données en lecture, en simple consultation, et celles qui pourront être écrites par des tiers? de quoi ont besoin les gens de la logistique pour mieux gérer la production? comment faciliter les échanges avec les libraires et les bibliothèques? etc. Toutes ces questions sont concrètes, et plus on se les pose plus on a de chance d’avancer sur la nécessité d’avoir une politique d’exposition réticulaire des données de la maison d’édition, c’est à dire de mettre en place des APIs. »
Le post complet de Christian est ici, mais attention si vous allez sur son blog, vous allez lire ce post, et puis un autre, et puis encore un autre, et ce sera l’heure du dîner. .. Après le dessert, vous pouvez compléter vos lectures par « API or Platform » de Jean de La Rochebrochard sur Medium, qui fait le distingo entre les startups qui fournissent des APIs, et celles qui deviennent des plateformes.
« Soit. Une API BtoB (business to business) en « SaaS » (Software as as Service) est une technologie disponible pour des tierces parties afin de leur permettre d’en bénéficier (Algolia, Twilio, Stripe…). Vous vous appuyez sur ces technologies mais vous utilisez vos propres données.
Une plateforme est une utilité à partir de laquelle sont construite à la fois des « commodités » et une couche sociale : les filtres photos sur Instagram, le mapping sur Waze, des médias qui disparaissent sur Snapchat, des courses avec Uber… Une fois que vous avez suffisamment d’utilisateurs de votre plateforme, vous pouvez fournir à des tierces parties à la fois les données et la technologie (API), liées ensemble. Les startups et les développeurs n’utilisent pas seulement votre technologie mais également vos données.
Stratégie et développement de produits mis à part :
Les API, c’est de la technologie. La compétition sera rude, mais vous allez y arriver. Les Plateformes, c’est de la technologie + des données. Très peu réussisent à en créer, en vérité. »
Dans les exemples de plateformes cités, lorsqu’il est question de données il s’agit de données produites (sciemment ou non) par les utilisateurs des services. Pour le monde de l’édition, l’équation est un peu différente : les maisons d’édition disposent de données qui ne sont pas, pour la plupart, créées par des « utilisateurs ». Elles détiennent des ressources très variées et de grande valeur, au premier chef les œuvres dont les auteurs leur ont cédé les droits ( qu’il s’agisse d’ouvrages de littérature ou de livres pratiques, de livres scolaires ou de guides de voyage, ou de tout autre type d’ouvrage), mais aussi des données qui décrivent ces œuvres (les métadonnées), et les informations qui concernent la vie de ces œuvres.
Les maisons d’édition disposent donc de données (et quelles données !). Pour la technologie, elles se sont mises en route, mais il y a encore pas mal de chemin à faire. En commençant par offrir un accès contrôlé à certaines de leurs données via des APIs, peut-être pourraient-elles progresser plus rapidement sur ce chemin, en associant des développeurs talentueux à la réflexion sur de nouvelles manières de considérer leur catalogue, qui constitue l’essentiel de leur richesse.
Merci Virginie pour cette relance de la conversation.
Je pense que tout est dans ton paragraphe de conclusion. C’est ce sur quoi on doit poursuivre la réflexion — et de façon de plus en plus pressante, parce qu’on s’engage, je crois, dans une nouvelle période de transition pour le monde du livre… et qui sera probablement beaucoup plus violente que les précédentes.
Prends soin de ton cerisier — et de ton blogue!
Ping : Ma plus grande déception | Jeux de mots et d'images
L’intérêt ne manque pas !
Pour dire les choses comme elles sont : Babelio n’existerait pas sans les API d’Amazon, qui constituent le socle de données à partir desquelles nos lecteurs peuvent cataloguer et chroniquer leurs lectures.
Amazon a compris depuis bien longtemps tout l’intérêt qu’il pouvait tirer de la mise en place d’API. Mais lorsqu’on essaie de s’en affranchir pour travailler en direct avec les éditeurs, il existe de vrais blocages (chez certains en tout cas.)
Même dans un groupe que Clément et toi connaissez bien, contacté pour récupérer ses flux de métadonnées, qui plutôt que de les mettre à disposition pour valoriser son catalogue, nous propose de les acheter au motif qu’ils dépensent de l’argent pour les produire… A se demander s’ils facturent des droits au Magazine Littéraire ou à Télérama lorsqu’ils leur envoient une couverture pour illustrer un article…
Le premier niveau de données auquel l’éditeur peut donner accès est effectivement son catalogue de produits. Il n’est pas anodin que HBG ait ouvert une version pro de son site américain, avec la documentation d’implémentation de ses flux en libre accès…
Je suis confiant dans le fait que les mentalités vont évoluer et que ce n’est qu’une question de temps.
Et pour contrebalancer un peu ce que je disais sur Amazon, et qui pouvait sonner comme le sempiternel discours « ah-les-ricains-ont-tout-compris-en-France-on-est-toujours-en-retard », j’en profite pour citer un acteur pas né de la dernière pluie et qui distribue des données de qualité depuis bien longtemps : la BNF !
Les bibliothèques (enfin, certaines) s’appuient sur la récupération du catalogage BNF pour ne plus avoir à refaire le même travail localement, ce qui libère du temps pour d’autres missions de médiation. C’est une information très qualitative, que nous exploitons également sur Babelio.
L’autre souci du côté des « exploitants » potentiels d’API dont Babelio fait partie, c’est qu’il est plus facile de travailler sur des API universelles (Amazon, BNF, SUDOC etc.) que sur des API émanant d’éditeurs ou de groupes d’édition qui ne portent que sur des catalogues spécifiques. On peut produire des choses vraiment intéressantes pour l’utilisateur final avec les data complètes de la RATP ; c’est plus difficile si on n’a les infos que des lignes de métro 1 à 7.
@Guillaume Bien sûr. Certains cas d’usage requièrent l’exhaustivité, et d’autres non.
Ce qui est difficile, du côté de l’éditeur, c’est d’adopter une logique qui est complètement antagoniste à sa culture d’origine, et en fait aussi à son modèle économique d’origine. Celui-ci est fondé sur le fait de disposer des droits que l’auteur lui confie par contrat, de manière exclusive : le travail de l’auteur comme celui de l’éditeur sont rémunérés par les ventes d’ouvrages. Le souci de se réserver l’exclusivité de ces ventes, , de ne pas autoriser la copie, est inhérent au modèle économique qui soutient l’activité. Les métadonnées sont elles aussi considérées comme un bien précieux, le fruit d’un travail (ce qu’elles sont, elles ne tombent pas du ciel…), dont la circulation se fait de manière la plus contrôlée possible et uniquement à des fins de promotion.
Le plus difficile est de se représenter les multiples cas d’usages, et ils ne sont pas tous aussi simples à décrire que « fournir des métadonnées Babelio » (qui finalement, préfère avoir un seul interlocuteur…),, ils ne concernent pas exclusivement le catalogue complet, ils peuvent être liées à des segments particuliers de celui-ci, ils peuvent concerner le contenu des livres, les métadonnées, mais aussi potentiellement n’importe quelle information présente dans nos systèmes.
Il est peut-être plus simple de se représenter un besoin que l’on a soi-même ( comment obtenir les métadonnées de untel ?) que d’imaginer des propositions que l’on pourrait avoir pour répondre aux besoins supposés d’autres acteurs, ou de laisser d’autres acteurs accéder de manière contrôlée à des données pour en imaginer des usages nouveaux.